Dirty PageTable 2024 N1CTF pwn_heap_master
Last Update:
Page View: loading...
2024 N1CTF pwn_heap_master
前置
对cross-cache attack有基本了解
本文很多是参考这两位师傅的文章(bsauce&henry),但有些地方会做更详细的介绍
同时本文直接将dirtypagetable具体手法细节与题目结合起来讲
本人是赛棍,正式学习内核没多久,有错误的地方希望师傅提出建议
关于Dirty PageTable
通过目标存在的double-free/OOB/uaf漏洞转化为对用户页表pte的控制,结合用户态程序可以实现任意物理地址写和读,由于是data-only的手法,可以绕过现有的基本保护和实现逃逸,且正常情况下成功率极高。
分析题目
题目配置
题目链接pwn_heap_master
题目的内核版本是6.1.110,算是较高的版本了

同时该题目在启动内核后,运行根目录startjail,进入nsjail,因此该题目的目标是实现nsjail逃逸,而且会加载在/etc/nsjail/nsjail.conf的配置文件
1 | |
对于配置文件重点关注挂载了什么,以及禁用了哪些系统调用
可以明显看见挂载了/dev/safenote以及/dev/dma_heap,通过挂载了/dev/dma_heap已经明显告诉你本题可以用dirty pagetable的手法,而且拿着dma_heap这个显眼的东西去bing查找大概率会查到dirty pagetable相关的文章
1 | |
对于禁用的了系统调用,平时内核题所用的系统调用基本被禁用了,什么msg_msg,keyctl,等等都不能用了,pipe倒是还能用。
由于启用了nsjail,可以在nsjail.conf文件的mount部分添加一条这个方便把exp导入nsjail中
2
3
4
5
6
7{
src: "/exp"
dst: "/exp"
is_bind: true
nosuid: true
rw: true
}
目标驱动
在初始化驱动时,会创建一个名为safenote大小为192独立kmem_cache,且flags: 0x4052000 (SLAB_ACCOUNT | SLAB_PANIC | SLAB_STORE_USER | SLAB_HWCACHE_ALIGN)存在SLAB_ACCOUNT因此不会和原有的kmem_cache合并。
在创建成功后还进行了一波神秘的操作,其具体功能后面再说。
1 | |
然后是分析基本操作,本题只有ioctl有可用的操作
ioctl维护着一个堆指针的表
功能一:能够从safenote上面申请一个chunk,且保存在用户指定idx对应表里,最多可以同时申请0x100个
功能二:能够释放用户指定idx对应表里的地址,且清空地址
功能三:能够有一次机会释放用户指定idx对应表里的地址,但不清空地址
很明显的double free+cross-cache attack
1 | |
神秘操作
可以从代码很明显的看出是对kmem_cache对应结构体作出了一些修改,我们可以直接利用cat /proc/slabinfo查看safenote和正常的kmalloc-192有什么区别
或者用gef-kernel里面所带的指令slub-dump来查看
gef-kernel非常建议使用,不像pwndbg的slab指令没有完整的symbols就不能使用,gef-kernel应该是使用了搜索内存的方式直接dump出来,非常方便,除此之外还有很多好用的指令,比如p2v,v2p实现虚拟地址和物理地址的转化,在这题就非常好用
可以从图中看出safenotechunk大小是0x100,而正常kmalloc-192chunk大小是0xc0,所以可以确定神秘操作在干啥了
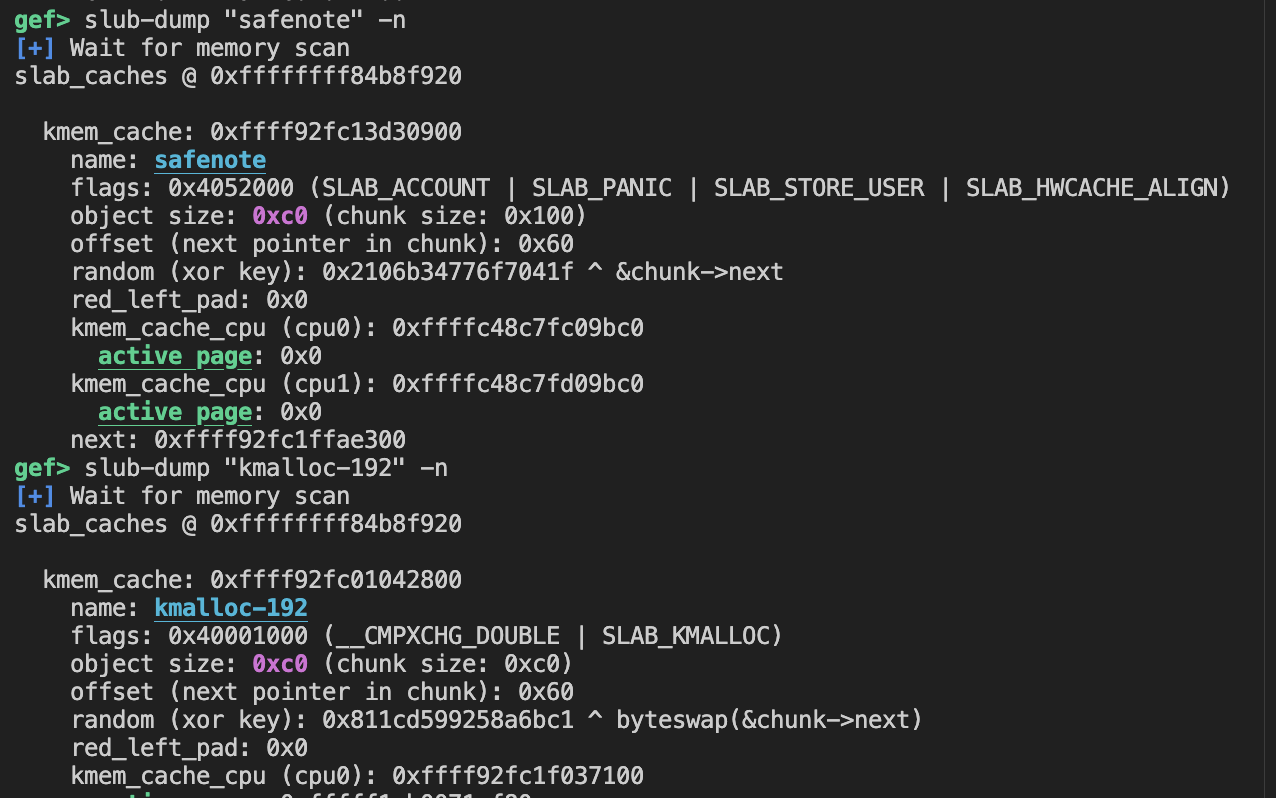
而将0xc0改成0x100有什么用呢,这里就是进一步告诉你使用file UAF,因为对于file结构体大小,申请的chunk大小也是0x100,利用上面的double-free可以很容易的实现file UAF
1 | |
漏洞利用
对于file UAF,很容易就能想到dirty cred来实现仅可读文件覆写,但是一方面对于该题的linux版本dirty cred能否还可以使用存在疑问,另一方面要实现逃逸只能去修改主机挂载过来的/bin文件夹(可能/proc下也有能用的),然后修改退出时执行的echo,可问题在于退出nsjail时,需要先退出exp,如果使用file UAF后退出时资源释放很大概率是会导致崩溃的
所以使用cross-cache attack+dirty pagetable来实现漏洞利用
第一步
实现file UAF
如果明白cross-cache attack这一步较为简单,首先是使用safenote直接kmalloc满0x100个chunk,然后全部free,留下一个用于double-free,根据chunk大小为0x100,一个page可以有16个chunk,safenote每次是申请一个slab都是一个page,0x100个chunk就是16个slab,同时该题最大留存的slab数量是4(神秘操作里有个除2操作,应该就是用于减小最大留存的slab数量,提高利用成功率),如果0x100个chunk全部释放则有12个slab会被释放,即有12个page被释放回buddy system
然后就是一次性打开大量的同一个任意文件,喷射file结构体,使得之前释放的page立马被再次拿来使用,而且buddy system也是遵循FILO,所以极高概率是申请回之前释放的page。
喷射完毕后我们使用safenote的free函数,free掉刚才保留的指针,此时有一个file struct被释放了。
接下来就是确定哪一个fd对应的file结构体被释放了,可以再次喷射大量的另一个文件的file struct,使得之前被释放的file struct被占用,现在循环read之前喷射的fd,如果有不一样的,则是victim fd。
第二步
现在将除了victim fd以外的fd全部close,由于有两个fd指向了同一个file struct,则不需要close victim fd,刚才kmalloc大量的file struct,全部file stuct释放后,大部分的slab对应的page又会回到buddy system中
接下来就要讲关于dirty pagetable的东西了
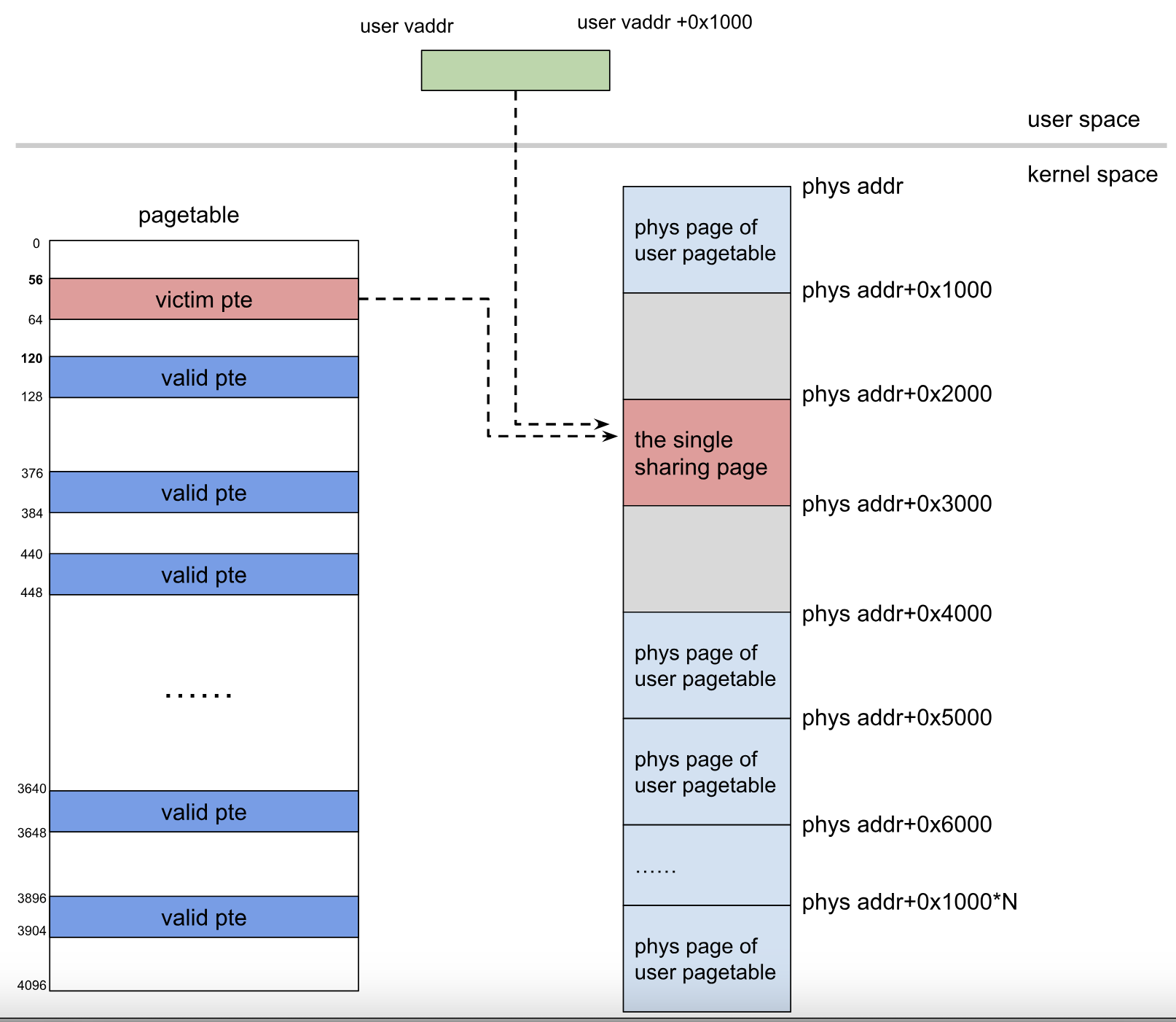
众所周知,每一个用户态进程都有一个对应的页表,通常64位的linux使用的是4级页表
对应下图从PGD到PUD到PMD再到PTE,PTE就是指向具体物理地址的信息了
对于每一个页表或者页表目录都是1page大小,即4096byte,每个页表项都是占8字节,则每个page有512个页表项
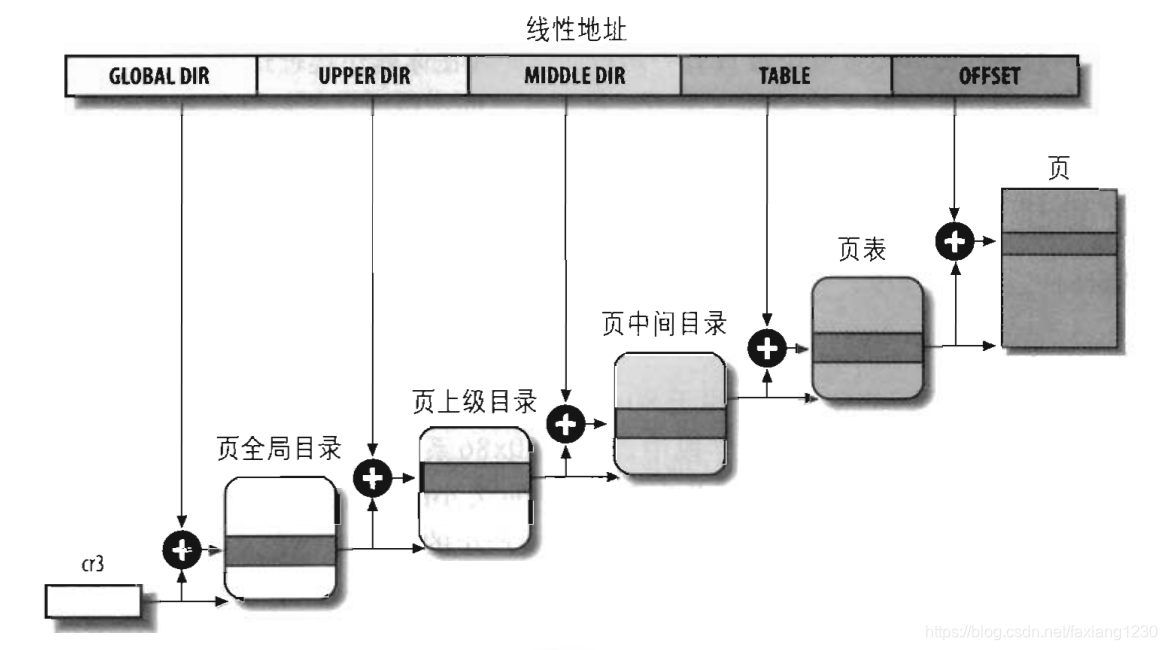
而对于一个用户态程序,可以看见有许多没有对应的物理地址的虚拟地址,这些虚拟地址我们可以使用mmap函数来映射对应的物理地址,在这些虚拟地址没被映射之前,其对应的页表目录是没有被创建的,显然不可能都创建的如果每个程序都将其的页表目录全部创建,那得占用很大一部分空间。
如果我们主动去mmap大量的地址则会有大量的1page从buddysystem中被申请出来,用于创建页表
需要注意mmap可以放在exp开始时直接执行,因为只有第一次读写对应mmap地址时,才会触发缺页然后映射对应的物理地址以及可能创建对应的页表项
我们回到上面free掉所有的file struct,则会有大量的1page回到buddysystem中,然后去mmap大量的地址,这些1page又被拉回来使用,而其中有一部分地方是我们的uaf的file struct对应的地方。
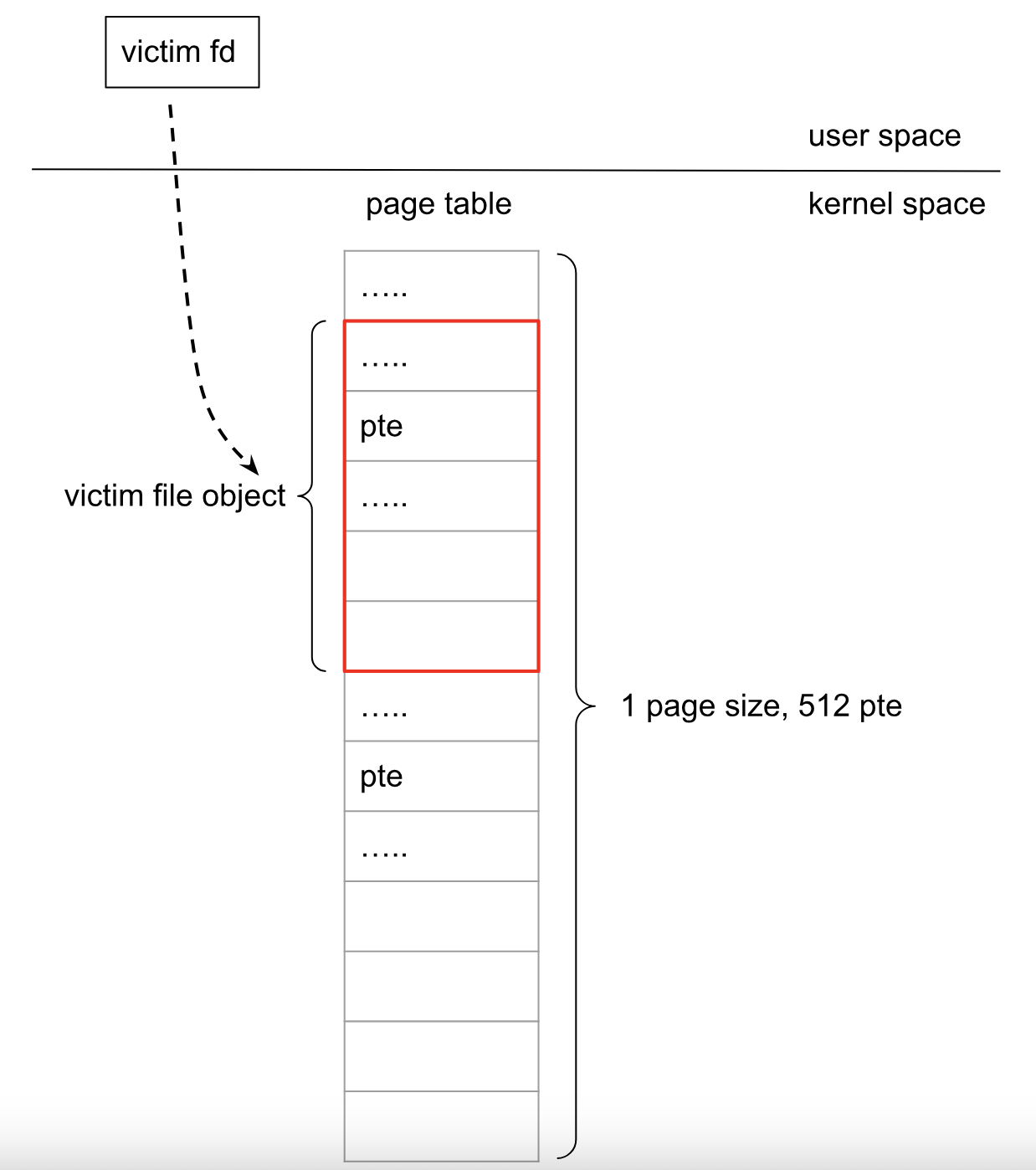
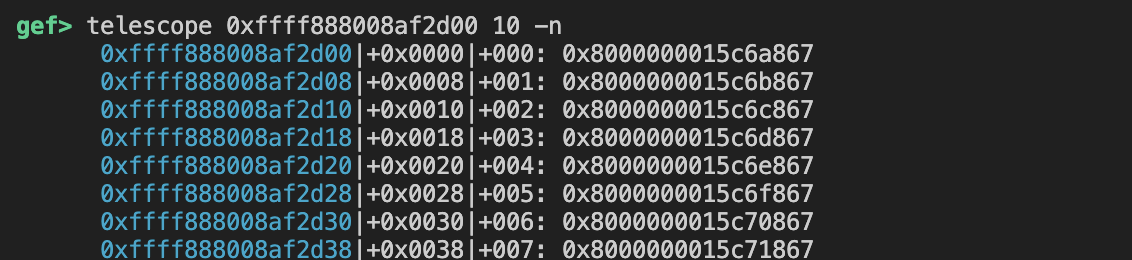
在内存中你会发现victim fd对应file struct的内容都是pte
里面最高位的8还有最低的3位867,应该都是一些标志位,去掉这些才是真正的物理地址
第三步
在此之前我们需要说一个file struct里的count成员(距离file struct开始地址0x38),他是用来表示当前有多少个引用指向该file结构体
如果用dup函数来复制victim fd,则会使得count+1,且即便file结构体内容不正常也能正常+1而不崩溃
如果dup,0x1000次则会使得pte对应的物理地址往下增加0x1000
真是佩服能找到这样一个功能适配dirty pagetable
但也很容易被修复,如果dup添加一个file struct 完整性验证,这个方法直接不能用了
而且每个用户态dup次数有限,可通过fork解决
当我们dup,0x1000次后,再次循环遍历之前mmap的地址,如果找到有一个和他本身应该对应的idx不一样的,则是victim page。
第四步
仅用dup也只能增加物理地址,似乎没啥用,有什么办法可以实现控制页表项呢
可能会想到继续dup,增加物理地址,直到找到包含页表项到page,实则目前是没法实现的
其实你会注意到一个问题,第二步,创建页表目录后,还有一个个page大小的映射被创建,相对于这一个个page大小的大量映射,之前file struct全部free释放的page似乎是非常少的不够用的,按理来说file struct里被写入pte成功率很低,但是第二步成功率非常高,则就说明了mmap映射的物理地址,和alloc页表目录对应的物理地址应该是来自不同区块的。同时mmap映射的物理地址比alloc页表目录对应的物理地址高。
匿名 mmap() 分配的物理页来自内存区的MIGRATE_MOVABLE free_area,而用户页表是从内存区的MIGRATE_UNMOVABLE free_area分配,所以很难通过递增PTE使之指向另一用户页表。
由于内核空间和用户空间需要一些共享物理页,使得两个空间都能访问到,比如dma-heap,io_uring,GPUs等
所以这里又要介绍另一个东西dma-heap,也是题目中nsjail挂载进来的/dev/dma-heap
我们可以通过打开/dev/dma-heap/system进行ioctl,分配一定大小的内存,该内存会在MIGRATE_UNMOVABLE free_area分配,而且该内存可以通过mmap映射到用户态空间。
1 | |
因此我们可以将页表目录的喷射改为,先喷射一半,然后进行dma-heap,再将另一半进行喷射
继续按之前的步骤,我们把victim page 先munmap,然后将dma-heap创建的地址mmap到victim page上面
记得读写,使得dma-heap对应的页创建
接下来再次进行多次dup,0x1000次,总有一次会使得victim page中对应的内容是pte
成功使得victim page里的内容是pte后,就可以开始尝试任意物理地址写读了吗?
该题目最终目的是实现逃逸,最好的想法就是patch内核的某个函数用户态触发执行实现逃逸,但是在开启aslr后物理地址里保存的text段的起始物理地址也是随机的
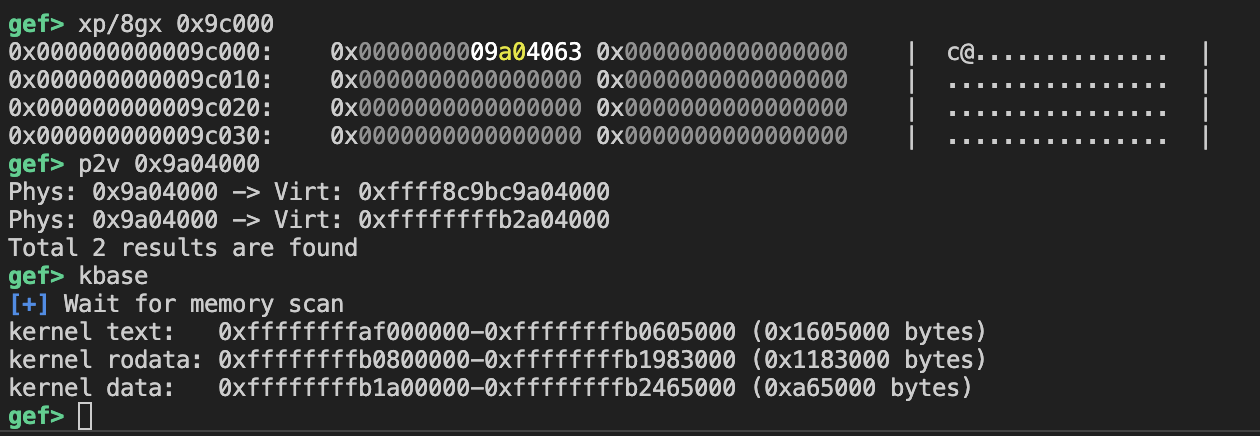
典中典类似page_offset_base+0x9d000保存着text地址,而page_offset_base+0x9c000(因为是直接映射区,对应的是物理地址的0x9c000)保存着物理地址的text地址
感觉既然都可以任意地址读,那也应该可以实现直接从0物理地址开始扫描,直到找到需要的物理地址吧?
接下来就是往victim page[0]写入0x9c000,然后去泄露物理地址的text地址,同时需要注意我们不知道是哪个mmap的地址的物理地址被改写为了0x9c000,所以还要再次进行搜索,得到victim page2
第五步
接下来直接模仿henry师傅文章里patch do_symlinkat函数
需要注意关闭kaslr时,0x9c000里保存的物理地址和物理地址的text基地址偏移量,与开启kaslr时不同,所以建议关闭kaslr时物理地址的text基地址直接使用0x1000000,测试成功后在开启kaslr然后调整
接下来就是将shellcode写入do_symlinkat起始地址
下面是汇编代码,也是直接拿henry师傅文章里的,然后通过nasm 来编译成elf文件,把shellcode提取出来即可
里面的各个函数偏移,还有sub r15,xxxxx的,还有current->fs的偏移需要我们修改
简单解释一下,call a使得当前do_symlinkat的地址被写到栈上,然后pop 给r15,计算text基地址,接下来就是修改当前的进程的cred,nsproxy,fs
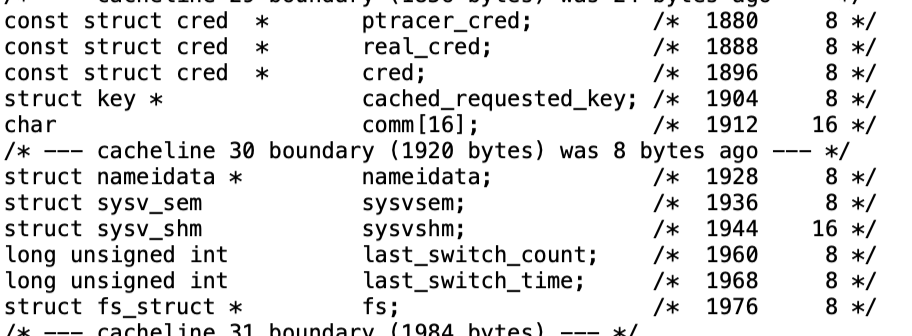
shellcode的fs替换是直接通过与指向task_struct偏移量来进行替换的,由于各个版本的fs_struct与task_struct的偏移量不同,所以需要特地计算
这边给出一个比较简单的方法,就是我们可以给进程取个名字,然后名字会保存在task_struct的成员comm里面,而通常comm成员与fs成员偏移量不变,可以先搜索comm里你指定的字符串,然后借此来计算得到fs与task_struct的偏移量
1 | |
然后在exp写入内存之前记得将shellcode的一些量比如0x1111111111111111替换为执行需要的值
接下来就是执行symlink触发shellcode,由于题目启动时使用的是将flag文件挂载为虚拟机的virtio类型的虚拟驱动器,shellcode执行成功后接下来就是读取/dev/vda文件获取flag
exp:
1 | |